最近经常在哔哩轻小说上看书,想做一个爬虫制作成 Epub 文件,在 Apple Books 上阅读,网站html源码整体很好解析,但是文本内容针对特定字符做了替换,需要找到js代码中的字符对照表,才能解密。
js定位
通过阅读网页 html 可以发现文章内容为 id=acontent 的 div 中,所以找一下对这段操作的代码,可以定位到 themes/zhmb/css/jsreadtools.js 中的这段程序:
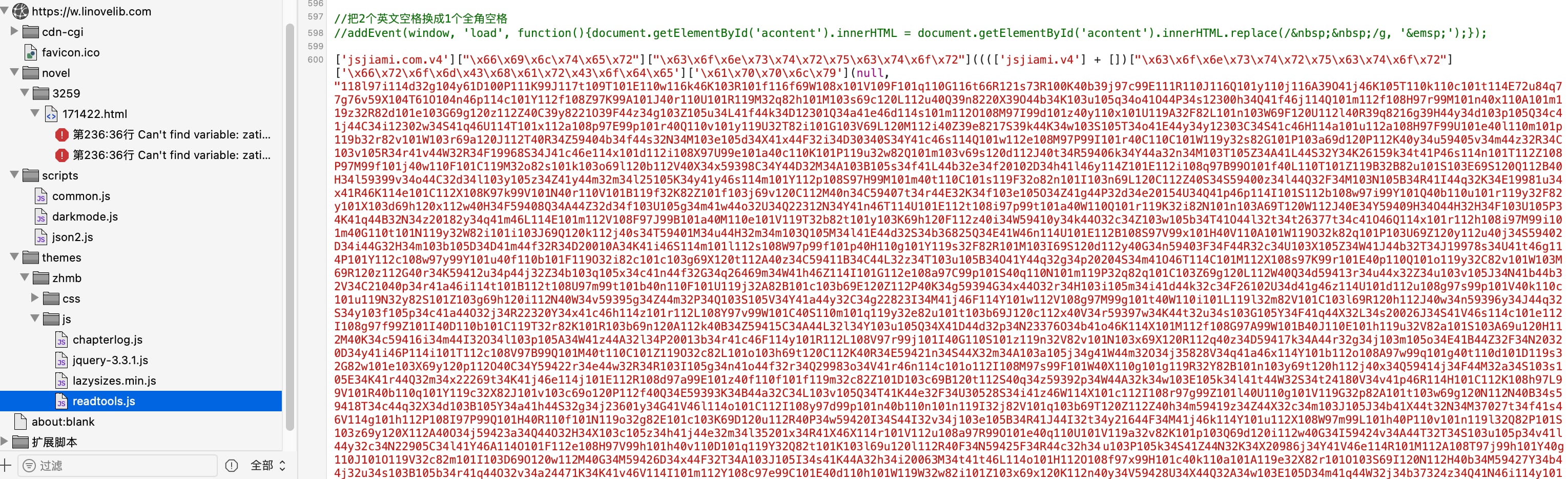
使用 jsjiami.com 解密后确定这段代码为加密源码
1
| ['jsjiami.com.v4']["filter"]["constructor"](((['jsjiami.v4'] + [])["constructor"]['fromCharCode']['apply'](null, ... ['split'](/[a-zA-Z]{1,}/))))('jsjiami.com.v4');
|
利用Claude尝试阅读加密js源码
Claude 2 支持最高 10mb 大小的单个文件上下文,这里我们尝试用它来分析一下这部分代码在做什么:
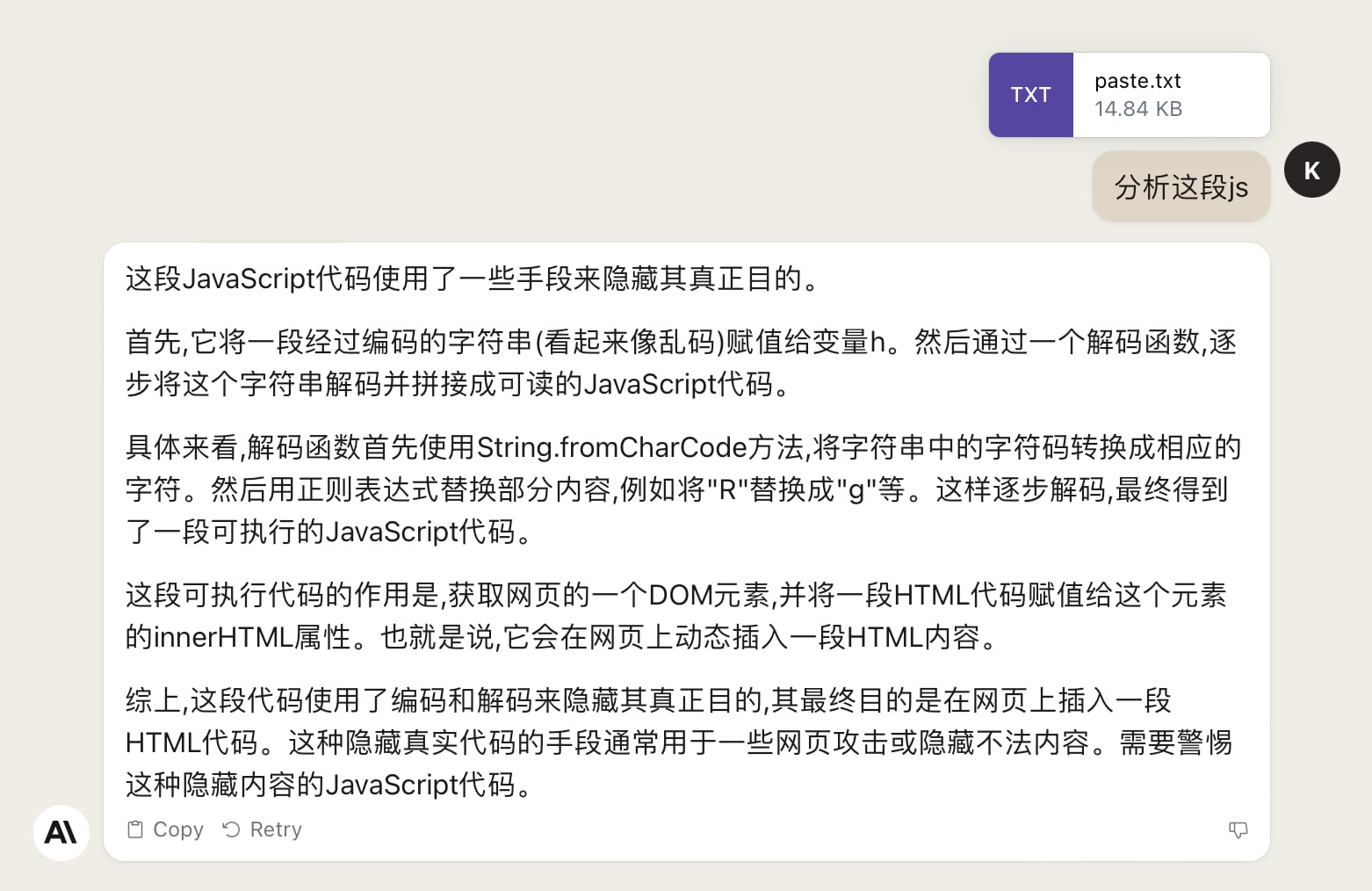
原理分析
通过 utf-8 将操作的 js 代码转换为一串数字,然后每隔两个字符中添加一个字母,这一段字符串就是需要解密的程序。
字符表提取程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| def decrypt_string(encrypted_string):
decrypted = ""
num_str = ""
for char in encrypted_string:
if char.isalpha():
if num_str:
num = int(num_str)
if num <= 128:
decrypted += chr(num)
else:
decrypted += str(num)
num_str = ""
else:
num_str += char
return decrypted
decrypted_string = decrypt_string(encode_text)
decoded_string = decrypted_string.encode('utf-8').decode('unicode-escape')
|
解码后这段程序长这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| var h=document.getElementById('acontent').innerHTML;
h=h.replace(new RegExp('8220',"gi"),"12300")
.replace(new RegExp('8221',"gi"),"12301")
.replace(new RegExp('8216',"gi"),"12302")
.replace(new RegExp('8217',"gi"),"12303")
.replace(new RegExp("59404", "gi"), "的")
.replace(new RegExp("59405", "gi"), "一")
.replace(new RegExp("59406", "gi"), "是")
.replace(new RegExp("59398", "gi"), "了")
.replace(new RegExp("59399", "gi"), "我")
.replace(new RegExp("59400", "gi"), "不")
.replace(new RegExp("59407", "gi"), "人")
.replace(new RegExp("59408", "gi"), "在")
...
|
这里注意下字符的编码,找到字符对照表:
1
2
3
4
5
6
7
8
9
10
11
12
13
| ['“', '「']
['”', '」']
['‘', '『']
['’', '』']
['\ue80c', '的']
['\ue80d', '一']
['\ue80e', '是']
['\ue806', '了']
['\ue807', '我']
['\ue808', '不']
['\ue80f', '人']
['\ue810', '在']
...
|
最后每个字符分别检查替换即可。
总结
从难度角度出发,获取解码方式不算难,重点是如何在网页源文件中找到操作的代码。